引言:
本系列是根据《Mastering Python NetworkingThird Edition》翻译整理出来的,原著作者:Eric Chou,大家可以关注一下。
随着网络工程领域的快速变化,我们无疑也经历了类似的变化。
随着软件开发越来越多地集成到网络的各个方面、传统的命令行接口和垂直集成中,网络堆栈方法不再是管理当今网络的最佳方法。
对于网络工程师来说,我们所看到的变化充满了兴奋和机会,但却具有挑战性,特别是对于那些需要快速适应和跟上步伐的人来说。
这本书是为了通过提供一个实用的指南,说明如何从一个传统的平台发展到一个基于软件驱动的实践,来帮助缓解网络专业人员的过渡。
在本书中,我们使用Python作为掌握网络工程任务的编程语言。
一个变革的时代为技术进步提供了巨大的机会。
Who this book is for❓
这本书是理想的IT专业人员和操作工程师,他们已经管理了网络设备组,并希望扩展他们关于使用Python和其他工具来克服网络挑战的知识。
建议使用网络和Python方面的基本知识。
What this book covers❓
第1章,回顾TCP/IP协议套件和Python,回顾了构成当今互联网通信的基本技术,从OSI和客户端服务器模型到TCP、UDP和IP协议套件。本章将回顾Python语言的基础知识,如类型、操作符、循环、函数和包。第2章,低级网络设备交互,使用实际的例子来说明如何使用Python在网络设备上执行命令。它还将讨论在自动化中使用只使用cli的接口所面临的挑战。本章将使用预期库、帕拉米科库、Netmiko库和Nornir库作为示例。第3章,api和意图驱动的网络,讨论了支持应用程序编程接口(api)和其他高级交互方法的新型网络设备。它还演示了允许抽象低级任务的工具,同时重点关注网络工程师的意图。关于思科NX-API、Meraki、Juniper PyEZ、Arista Pyeapi, and Vyatta VyOS的讨论和例子将出现在本章中。第4章,Python自动化框架-允许的基础,讨论了允许的基础,一个开源的,基于Python的自动化框架。允许从api更进一步,专注于声明性任务意图。在本章中,我们将介绍使用安易许及其高级体系结构的优点,并查看使用思科、瞻博和Arista设备的一些实际例子。第5章,Python自动化框架——超越基础知识,建立在上一章的知识基础上,并涵盖了更高级的可允许的主题。我们将涵盖条件条件、循环、模板、变量、可允许的保险库和角色。它还将涵盖编写定制模块的基础知识。第6章,使用Python的网络安全,介绍了几个Python工具来帮助您保护网络的安全。它将讨论使用Scapy进行安全测试,使用anssable快速实现访问列表,以及使用Python进行网络取证分析。第7章,使用Python的网络监控-第1部分,涵盖了使用各种工具监控网络。本章包含了一些使用SNMP和PySNMP进行查询以获取设备信息的示例。矩阵库和Pygal的例子将显示为绘制结果。本章将以一个使用Python脚本作为输入源的Cacti示例结束。第8章,使用Python的网络监控-第2部分,涵盖了更多的网络监控工具。本章将从使用Graphviz从LLDP信息中绘制网络图开始。我们将转向使用网络流和其他技术来使用基于推送的网络监控的示例。我们将使用Python来解码流包,并使用ntop来可视化结果。本文还将介绍弹性搜索以及如何将它用于网络监视。第9章,使用Python构建网络Web服务,向您展示了如何使用Python烧瓶Web框架来创建我们自己的网络自动化API。网络API提供了一些好处,例如从网络详细信息中抽象出请求者、整合和自定义操作,以及通过限制可用操作的公开来提供更好的安全性。第10章,AWS云网络,展示了我们如何使用AWS来构建一个具有功能性和有弹性的虚拟网络。我们将介绍虚拟私有云技术,如云形成、VPC路由表、访问列表、弹性IP、NAT网关、直接连接和其他相关主题。第11章,Azure云网络,涵盖了Azure的网络服务,以及如何利用该服务构建网络服务。我们将讨论Azure VNet、快速路由和VPN、Azure网络负载均衡器,以及其他相关的网络服务。第12章,使用弹性堆栈的网络数据分析,展示了我们如何使用弹性堆栈作为一组紧密集成的工具来帮助我们分析和监控我们的网络。我们将涵盖从安装、配置、数据导入与Logstash和节拍,以及使用弹性搜索搜索数据,到使用Kibana可视化的领域。第13章,与Git合作,我们将说明如何利用Git进行协作和代码版本控制。本章将使用使用Git进行网络操作的实际例子。第14章,与詹金斯的持续集成,使用詹金斯自动创建操作管道,可以节省我们的时间和增加可靠性。第15章,网络的测试驱动开发,解释了如何使用Python的单元测试和小测试来创建简单的测试来验证我们的代码。我们还将看到为网络编写测试来验证可达性、网络延迟、安全性和网络事务的例子。我们还将看到如何将测试集成到连续集成工具中,如Jenkins。To get the most out of this book
为了最大限度地利用这本书,我们推荐了一些基本的实践网络操作知识和Python知识。
大多数章节可以按任何顺序阅读,除了第4章和第5章,它们应该按顺序阅读。
除了在书的开头所介绍的基本的软件和硬件工具外,与每个章节相关的新工具也将在各自的章节中被介绍。
强烈建议遵循并实践您自己的网络实验室中显示的例子。正文
第一章--Review of TCP/IP Protocol Suite and Python
欢迎来到网络工程的新时代!
多年来,DevOps和软件定义网络(SDN)运动等因素,已经显著地模糊了网络工程师、系统工程师和开发人员之间的界限。
你拿起这本书的事实表明,你可能已经是网络DevOps的采用者,或者你正在考虑检查网络的可编程性。
也许你和我一样,已经做了一名网络工程师多年了,并且想知道关于Python编程语言的热门话题是什么。
您甚至可能已经流利地掌握了Python编程语言,但您想知道它在网络工程领域的应用程序是什么。
如果你属于这些阵营,或者只是对网络工程领域的Python感到好奇,我相信这本书是适合你的:

这本书假设您有一些管理网络的实际经验,以及对网络协议的基本理解。
如果您已经熟悉Python作为一种语言,这很有帮助,但是我们将在本章的后面介绍一些基础知识。
你不需要成为Python或网络工程方面的专家来最大限度地发挥这本书。
这本书打算建立在网络工程和Python的基本基础上,以帮助读者学习和实践各种应用程序,可以使他们的生活更容易。
本章将快速访问相关的网络话题,而不涉及太多的细节。从我在现场工作的经验,一个典型的网络工程师或开发人员可能不记得确切的传输控制协议(TCP)状态机来完成他们的日常任务(我知道Idon),但他们会熟悉开放系统互连(OSI)模型,TCP和用户数据报协议(UDP)操作,不同的IP头字段,和其他基本概念。我们还将查看Python语言的高级评论;对于那些不每天用Python编写的读者来说,他们有理由阅读书的其余部分。
具体来说,我们将涵盖以下主题:
• An overview of the internet -- 📍
• The OSI and client-server model -- 📍
• TCP, UDP, and IP protocol suites -- 📍
• Python syntax, types, operators, and loops -- 📍
• Extending Python with functions, classes, and packages --📍
当然,本章所提供的资料并不详尽;如果需要,请查阅参考资料。
作为网络工程师,我们通常会受到我们需要管理的网络的规模和复杂性的挑战。
它们的范围从小型家庭网络、制造小型企业的中型网络,到跨越全球的大型跨国企业网络。
其中最大的网络,当然是互联网。如果没有互联网,就不会有电子邮件、网站、API、流媒体或我们所知的云计算。
因此,在我们更深入地了解协议和Python的细节之前,让我们先概述一下互联网。
• An overview of the internet
❓❓❓ Servers, hosts, and network components
❓❓❓ The rise of data centers
❓❓❓ Enterprise data centers
❓❓❓ Cloud data centers
❓❓❓ Edge data centers什么是互联网?
对于网络工程师来说,因特网是一个全球计算机网络,由一个将大小网络连接在一起的互联网络组成。换句话说,它是一个没有集中式所有者的网络网络。以你的家庭网络为例。它可能包括一个集成了路由、以太网交换和无线接入点功能的设备,它们将智能手机、平板电脑、电脑和互联网电视连接在一起,以便这些设备相互通信。这是您的局域网(LAN)。
当你的家庭网络需要与外部世界通信时,它会将信息从你的局域网传输到一个更大的网络,通常被恰当地命名为互联网服务提供商(ISP)。ISP通常被认为是一个你付费上网的业务。他们能够通过将小型网络聚合到他们所维护的更大的网络中来做到这一点。您的ISP网络通常由边缘节点组成,这些节点将流量聚合到其核心网络中。核心网络的功能是通过一个更高速的网络来连接这些边缘网络。
在特殊的边缘节点上,ISP将连接到其他ISP,以便适当地将流量传递到目的地。
从您的目的地到您的家庭电脑、平板电脑或智能手机的返回路径可能遵循,也可能不遵循相同的路径,通过所有这些网络返回到您的设备,而源和目的地保持不变。让我们来看看组成这个网络网络的组件。
主机是网络上与其他节点进行通信的终端节点。
在当今世界,主机可以是传统的电脑,也可以是你的智能手机、平板电脑或电视。随着物联网(IoT)的兴起,主机的广义定义可以扩展到包括互联网协议(IP)相机、电视机顶盒,以及我们在农业、农业、汽车等领域使用的不断增长的传感器类型。
随着连接到互联网上的主机数量的激增,所有这些主机都需要被寻址、路由和管理。对适当网络的需求从未如此大。
大多数时候,当我们在互联网上时,我们会请求服务。
这可以是查看一个网页,发送或接收电子邮件,传输文件,等等。这些服务均由服务器提供。
顾名思义,服务器为多个节点提供服务,并且通常具有更高级级的硬件规范。
在某种程度上,服务器是网络上的特殊超级节点,可以为它们的对等节点提供额外的功能。
稍后,我们将在客户端服务器模型部分中查看服务器。
如果您把服务器和主机看作是城市和城镇,那么网络组件就是将它们连接在一起的道路和高速公路。
事实上,当描述在全球各地传输不断增长的比特和字节的网络组件时,人们就会想到信息高速公路这个术语。
在我们将稍微讨论的OSI模型中,这些网络组件是第一层到三层的设备,有时也会冒险进入第四层。
它们是指导通信的第二层和第三层路由器和交换机,以及第一层传输,如光纤电缆、同轴电缆、双绞铜对和一些密集波分复用(DWDM)设备等等。
总的来说,主机、服务器、存储和网络组件构成了我们今天所知的互联网。
在最后一节中,我们将了服务器、主机和网络组件在网络中扮演的不同角色。
由于服务器需要更高的硬件容量,它们通常被放在一个中心位置,以更有效地管理。
我们经常将这些位置称为数据中心。
在一个典型的企业中,公司通常有对内部工具的业务需求,如电子邮件、文档存储、销售跟踪、订购、人力资源工具和知识共享内部网。
这些服务可以转换为文件服务器和邮件服务器、数据库服务器和web服务器。
与用户计算机不同,这些计算机通常是需要大量电源、冷却和网络连接的高端计算机。
硬件的一个副产品也是它们产生的噪音,这不适合正常的工作空间。
服务器通常被放置在企业建筑中的一个中心位置,称为主配线架(MDF),以提供必要的电力馈电、电力冗余、冷却和网络连接。
为了连接到MDF,用户的流量通常聚集在离用户更接近的位置,这有时被称为中间分发帧(IDF),然后它们被捆绑并连接到MDF。
IDFMDF的传播遵循企业建筑或校园的物理布局并不罕见。
例如,每个建筑楼层可以由一个IDF组成,该IDF聚合到同一建筑的另一楼层的集中MDF。
如果企业由多个建筑物组成,则可以在将这些建筑物连接到企业数据中心之前,通过合并这些建筑物的流量来完成进一步的聚合。
企业数据中心一般遵循三层的网络设计。这些层是访问层、分布层和核心层。
当然,和任何设计一样,都没有硬性规则或一刀切的模型;三层设计只是一个通用的指南。
例如,要将三层设计覆盖到前面的User-IDF-MDF示例中,访问层类似于每个用户连接到的端口,IDF可以看作是分发层,而核心层由与MDF和企业数据中心的连接组成。
当然,这是对企业网络的一种概括,因为其中一些网络不会遵循相同的模型。
随着云计算和软件,或基础设施即服务(IaaS)的兴起,云提供商所建立的数据中心规模非常大,有时被称为超规模的数据中心。
我们所说的云计算是由亚马逊、微软和谷歌等公司提供的计算资源的按需可用性,而用户不必直接管理这些资源。
由于它们需要容纳的服务器数量,云数据中心通常比任何企业数据中心都需要更高的电力、冷却和网络容量。
即使在云提供商数据中心工作了多年之后,每次我访问云提供商数据中心时,我仍然对它们的规模感到惊讶。
举例来说,云数据中心,其规模如此庞大且耗电,它们通常建在发电厂附近,在那里它们可以获得最便宜的电价,而在电力运输过程中不会失去太多的效率。
他们的冷却需求如此之高,以至于一些人被迫创造性数据中心的位置。
例如,Facebook在瑞典北部(北极圈以南仅70英里)建立了柳乐亚数据中心,部分原因是利用低温来降温。
在为亚马逊、微软、谷歌和Facebook建立和管理云数据中心方面,任何搜索引擎都可以给你一些令人震惊的数字。
例如,位于爱荷华州西得梅因的微软数据中心包括200英亩土地上的120万平方英尺的设施,并要求该市花费估计6500万美元进行公共基础设施升级。

在云提供商的规模上,他们需要提供的服务通常不具有成本效益,或无法容纳在单个服务器中。
服务分布在服务器之间,有时跨越许多不同的机架,为服务所有者提供冗余和灵活性。
延迟和冗余需求以及服务器的物理扩展给网络带来了巨大的压力。
连接服务器机队所需的互连数量相当于电缆、交换机和路由器等网络设备的爆炸性增长。
这些需求转化为这些网络设备需要被存储、供应和管理的次数。
一个典型的网络设计应该是一个多阶段的,Clos网络:

在某种程度上,云数据中心是网络自动化成为速度、灵活性和可靠性的必要条件。
如果我们遵循通过终端和命令行接口来管理网络设备的传统方法,那么所需的工程小时数将不允许该服务在合理的时间内可用。
更不用说,人类的重复容易出错,效率低,而且是对工程人才的可怕浪费。
为了进一步增加复杂性,通常需要快速更改一些网络配置,以适应快速变化的业务需求。
就我个人而言,云数据中心是我几年前用Python开始走网络自动化道路的地方,从那以后我就再也没有回头过。
如果我们在数据中心级别有足够的计算能力,为什么除了在这些数据中心之外还要保留任何东西呢❓
来自世界各地客户机的所有连接都可以路由回提供该服务的数据中心服务器,我们可以就此结束,对吧?
答案是,当然,这取决于用例。
将请求和会话从客户端路由到大型数据中心的最大限制是传输中引入的延迟。
换句话说,较大的延迟是网络成为瓶颈的地方。
当然,任何一本基础物理教科书都可以告诉你,网络延迟数永远不会是零:即使光在真空中传播的速度一样快,物理运输仍然需要时间。
在现实世界中,延迟将比真空中的光要高得多。
为什么因为网络包必须通过多个网络,有时是通过海底电缆、慢速卫星链路、3G或4G蜂窝链路,或Wi-Fi连接。
如果我们需要减少网络延迟怎么办❓
一种解决方案是减少最终用户请求所遍历的网络数量。
在用户进入网络的边缘与最终用户尽可能紧密地连接,并在边缘位置放置足够的资源来为请求提供服务。
这在服务诸如音乐和视频等媒体内容时尤其常见。
让我们花点时间想象一下,你正在构建下一代的视频流媒体服务。
为了提高客户对流畅流媒体的满意度,您将希望将视频服务器尽可能靠近客户,或在内部或非常接近客户的ISP。
此外,为了冗余和连接速度,视频服务器场的上行不仅连接到一两个isp,还连接到我可以连接的所有isp,以减少跳数。
所有的连接都需要尽可能多的带宽来减少峰值时段的延迟。
这种需求催生了大型ISP和内容提供商的边缘数据中心。
即使网络设备的数量没有云数据中心那么高,它们也可以从网络自动化中受益,以提高网络自动化所带来的可靠性、灵活性、安全性和可见性。
我们将在本书的后面章节中介绍安全性(Chapter 6, Network Security with Python)和可见性(Chapter 7, Network Monitoring with Python – Part 1, and Chapter 8, Network Monitoring with Python – Part 2)。
与许多复杂的主题一样,它们通过将主题划分为更小的消化部分来打破复杂性,网络也是基于层次的概念的。
多年来,人们发展出了不同的网络模式。我们将看看这本书中两个最重要的模型,从OSI模型开始。
• The OSI and client-server model
❓❓❓ The OSI model
❓❓❓ Client-server model
❓❓❓ Network protocol suites
❓❓❓ The transmission control protocol
❓❓❓ Functions and characteristics of TCP
❓❓❓ TCP messages and data transfer
❓❓❓ The user datagram protocol❓❓❓ The internet protocol
❓❓❓ IP routing concepts没有首先检查OSI模型,没有一本网络书是完整的。
该模型是一个概念模型,将电信功能组成为不同层次的概念模型。
该模型定义了七层,每一层独立地位于另一个具有定义结构和特征的层之上。
例如,在网络层中,IP位于不同类型的数据链路层的顶部,如以太网或帧中继。
OSI参考模型是将不同和不同的技术标准化为一组人们可以达成一致的共同语言的好方法。
这大大减少了在单个层上工作的团队的范围,并允许他们深入研究特定的任务,而不必太担心兼容性:

OSI模式最初是在20世纪70年代后期提出的,后来由国际标准化组织(ISO)联合出版,该组织现在被称为国际电信联盟(ITU-T)的电信标准化部门。
在引入电信中的一个新主题时,它被广泛接受和普遍提及。
大约在OSI模型开发的同一时期,互联网正在形成。
原始设计者使用的参考模型通常被称为TCP/IP模型。
TCP和IP是设计中包含的原始协议套件。
这与OSI模型有点类似,因为它们将端到端数据通信划分为抽象层。
不同之处在于,该模型组合在应用层的OSI模型中的第5到第7层,而物理链路层和数据链路层组合在链路层中:

OSI和TCP/IP模型对于提供端到端数据通信的标准都很有用。
然而,在大多数情况下,我们将在这本书中更多地参考TCP/IP模型,因为这是互联网最初是建立在其基础上的。
我们将在需要时参考OSI模型,例如当我们在接下来的章节中讨论web框架时。
就像传输层的模型一样,也有管理应用程序级别通信的参考模型。
在现代网络中,大多数应用程序都基于客户机-服务器模型。
我们将在下一节中介绍客户机-服务器模型
客户机-服务器引用模型演示了两个节点之间的数据通信的标准方法。
当然,到目前为止,我们都知道,并不是所有的节点都是平等的。
即使在最早的高级研究计划局网络(阿帕网)时代,也有工作站节点,也有服务器节点,目的是向其他节点提供内容。
这些服务器节点通常具有更高的硬件规范,并由工程师更严格地进行管理。
由于这些节点为其他人提供资源和服务,因此它们被适当地称为服务器。
服务器通常闲置着,等待客户端启动对其资源的请求。
客户机请求请求的分布式资源模型称为客户机-服务器模型。
为什么这很重要❓
如果您思考一下,这个客户机-服务器模型大大强调了网络的重要性。
如果不需要在客户端和服务器之间传输服务,网络互连就不太需要。
将位和字节从客户端传输到服务器的需要揭示了网络工程的重要性。
当然,我们都知道,其中最大的网络互联网是如何改变我们所有人的生活,并在继续这样做。
您可能会问,每个节点如何确定它们每次需要相互交谈时的时间、速度、源和目的地❓
这就给我们带来了网络协议。
在计算机网络的早期,协议是专有的,并由设计连接方法的公司密切控制。
如果您在主机中使用Novell的IPX/SPX协议,那么相同的主机将无法与苹果的AppleTalk主机进行通信,反之亦然。
这些专有的协议套件通常具有与OSI参考模型类似的层,并遵循客户机-服务器之间的通信方法,但彼此之间不兼容。
专有协议通常只在封闭的局域网中工作,而不需要与外部世界进行通信。
当流量确实需要超越本地局域网时,通常会使用一个互联网转换设备,如路由器,来从一个协议转换到另一个协议。
例如,为了将一个基于AppleTalk的网络连接到互联网上,一个路由器将被用于连接并将AppleTalk协议转换为一个基于ip的网络。
额外的翻译通常不是完美的,但由于大多数通信发生在早期的局域网内,它被网络管理员接受了。
然而,随着网络间通信的需求超过局域网,标准化网络协议套件的需求变得越来越大。
这些专有协议最终让位于由TCP、UDP和IP组成的标准化协议套件,这极大地增强了一个网络与另一个网络通信的能力。
互联网是其中最伟大的网络,它依赖于这些协议来正常运行。
在接下来的几节中,我们将详细介绍每个协议套件。
TCP是当今互联网上使用的主要协议之一。
如果您打开了一个网页或发送了电子邮件,您就遇到了TCP协议。
该协议位于OSI模型的第4层,它负责以可靠和错误检查的方式在两个节点之间交付数据段。
TCP由一个160位的报头组成,其中包括一个源端口和目标端口、一个序列号、一个确认号、一个控制标志和一个校验和:

TCP使用数据报套接字或端口来建立主机与主机之间的通信。
这个标准机构被称为互联网号码分配机构(IANA),它指定了著名的端口来指示某些服务,例如HTTP(web)的端口80和SMTP(邮件)的端口25。
客户机-服务器模型中的服务器通常会侦听这些已知的端口之一,以便接收来自客户机的通信请求。
TCP连接由操作系统由表示连接的本地端点的套接字管理。
协议操作由一个状态机组成,在通信会话期间,机器需要跟踪它何时监听传入的连接,以及在连接关闭后释放资源。
每个TCP连接都要经过一系列的状态,例如 Listen, SYN-SENT, SYN-RECEIVED, ESTABLISHED, FIN-WAIT, CLOSE-WAIT, CLOSING, LAST-ACK, TIME-WAIT, and CLOSED.
TCP和UDP在同一层的UDP之间最大的区别是它以有序和可靠的方式传输数据。
TCP操作保证交付这一事实通常将TCP称为面向连接的协议。
它首先建立一个三向握手来同步发射机和接收机、SYN、SYN-ACK和ACK之间的序列号。
确认用于跟踪对话中的后续片段。
最后,在对话结束时,一方发送FIN消息,另一方发送FIN消息,并发送自己的FIN消息。
然后,FIN启动器将自动接收到它收到的FIN消息。
正如我们很多处理过TCP连接问题的人可以告诉你的那样,操作可能会变得相当复杂。
人们当然可以理解,大多数时候,操作只是在后台无声地进行。
关于TCP协议可以写一整本书;事实上,许多优秀的书已经写了关于协议的。
❗TIPS:
由于本节是一个快速的概述,如果感兴趣,TCP/IP指南(http://www.tcpipguide.com/)是一个优秀的免费资源,您可以使用它来深入研究这个主题。
UDP也是互联网协议套件的核心成员。
与TCP一样,它在OSI模型的第4层上进行操作,该层负责在应用程序和IP层之间交付数据段。
与TCP不同,报头只有64位,它只包含一个源端口和目标端口、长度和校验和。
轻量级标头使它非常适合更快的应用程序,而不需要设置两个主机之间的会话或需要可靠的数据传输。
也许很难想象今天的快速互联网连接,但额外的头对X.21和早期的帧中继链接的传输速度有很大的不同。
除了速度差异外,不需要保持各种状态,如TCP,也节省了两个端点上的计算机资源:

你现在可能想知道为什么UDP在现代被使用;考虑到缺乏可靠的传输,我们不希望所有的连接都是可靠和无错误的吗❓
如果您考虑到多媒体视频流或Skype调用,那么当应用程序只是想要尽快交付数据报时,这些应用程序将受益于更轻的报头。
您还可以考虑基于UDP协议的快速域名系统(DNS)查找过程,其中准确性和延迟之间的权衡通常会导致较小的延迟。
当您在浏览器上输入的地址被转换成一个计算机可理解的地址时,用户将从一个轻量级的过程中受益,因为这必须在甚至在第一个比特的信息从您最喜欢的网站传递给您之前发生。
同样,本节并没有公正地描述UDP的主题,如果您有兴趣了解更多关于UDP的内容,我们鼓励读者通过各种资源来探索这个主题。
❗TIPS:
维基百科上关于UDP的文章,https://en.wikipedia.org/ wiki/User_Datagram_Protocol,是了解更多关于UDP的一个很好的起点。
正如网络工程师会告诉你的那样,我们生活在IP层,即OSI模型的第3层。
IP在端节点之间的寻址和路由等任务。一个IP的寻址可能是它最重要的工作。
地址空间分为两部分:网络部分和主机部分。
子网掩码用于通过匹配网络地址中的主机部分,指示网络部分和主机部分由网络组成,主机部分是主机。
IPv4用虚线表示地址,例如,192.168.0.1。
子网掩码可以采用虚线表示法(255.255.255.0),也可以使用正斜杠表示网络位中应考虑的位数(/24):

IPv6头是IPv4的下一代IP头,具有固定部分和各种扩展头:
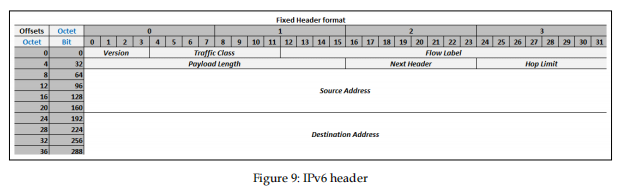
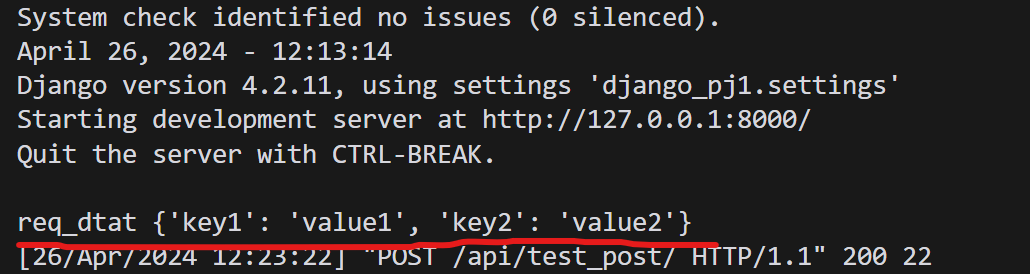
固定头部分中的IPv6下一个头字段可以指示要遵循的携带附加信息的扩展头。
还可以识别系统、TCP、UDP等上层协议。
扩展标头可以包括路由信息和片段信息。
尽管协议设计者希望从IPv4转移到IPv6,但今天的互联网仍然基本上使用IPv4解决,一些服务提供商网络内部使用IPv6解决。
固定头部分中的IPv6下一个头字段可以指示要遵循的携带附加信息的扩展头。还可以识别系统、TCP、UDP等上层协议。扩展标头可以包括路由信息和片段信息。尽管协议设计者希望从IPv4转移到IPv6,但今天的互联网仍然基本上使用IPv4解决,一些服务提供商网络内部使用IPv6解决。
NAT通常用于将一系列私有的IPv4地址转换为公开的可路由的IPv4地址。
但它也可能意味着IPv4到IPv6之间的转换,例如当运营商在网络内使用IPv6时,当数据包离开网络时需要转换为IPv4。
有时,出于安全原因,也会使用NAT6到6。
安全是一个连续的过程,它集成了网络的所有方面,包括自动化和Python。
这本书旨在使用Python来帮助您管理网络;安全将在书中下面的章节中进行讨论,比如使用Python来实现访问列表,在日志中搜索破坏,等等。
我们还将研究如何使用Python和其他工具来在网络中获得可见性,例如基于网络设备信息的动态的图形网络拓扑。
IP路由是关于让两个端点之间的中间设备基于IP报头传输它们之间的数据包。
对于所有通过互联网进行的通信,数据包将通过各种中间设备。
如前所述,中间设备由路由器、交换机、光学齿轮和各种其他不在网络和传输层之外进行检查的齿轮组成。
类似于公路旅行,你可以在美国从加利福尼亚州的圣地亚哥市旅行到华盛顿州的西雅图市。
IP源地址类似于圣地亚哥,目的地IP地址可以被认为是西雅图。
在你的公路旅行中,你会在许多不同的中间点停留,如洛杉矶、旧金山和波特兰;这些可以被认为是源和目的地之间的中间路由器和切换。
为什么这很重要?在某种程度上,这本书是关于管理和优化这些中间设备的。
在跨越多个足球场规模的大型数据中心时代,对高效、敏捷、可靠和经济的方法来管理网络的需求成为企业竞争的一个主要优势。
在接下来的章节中,我们将深入探讨如何使用Python编程来有效地管理网络。
现在我们已经研究了网络参考模型和协议套件,我们准备深入研究Python语言本身。
在本章中,我们将从Python进行全面概述。
• Python syntax, types, operators, and loops
❓❓❓ Python language overview
❓❓❓ Python versions
❓❓❓ Operating system简而言之,这本书是关于让我们的网络工程生活与Python一起更容易。
但是什么是Python,为什么它是许多DevOps工程师的语言❓
用Python基金会执行摘要( https://www.python.org/doc/essays/blurb/ )的话来说:
“Python是一种具有动态语义的可解释的、面向对象的高级编程语言。它的高级内置数据结构,结合动态类型和动态绑定,使其非常适合快速应用程序开发,以及作为脚本或粘合语言将现有组件连接在一起。Python的简单、易于学习的语法强调了可读性,因此降低了程序维护的成本。”
如果您对编程有点陌生,那么前面提到的面向对象的动态语义可能对您来说并没有多大意义。
但我认为我们都同意,快速的应用程序开发和简单、易于学习的语法听起来像是一件好事。
Python作为一种解释语言,意味着在执行之前几乎不需要任何编译过程,因此编写、测试和编辑Python程序的时间大大减少了。
对于简单的脚本,如果脚本失败,通常只需要调试一个打印语句。
使用解释器还意味着Python可以很容易地移植到不同类型的操作系统中,比如Windows和Linux,在一个操作系统上编写的Python程序可以在另一个操作系统上使用,而很少或没有更改。
这些函数、模块和软件包通过将一个大型程序分解成简单的可重用片段来鼓励代码重用。
Python的面向对象特性使它进一步将组件分组到对象中。
实际上,所有的Python文件都是可以重用或导入到另一个Python程序中的模块。
这使得在工程师之间共享程序变得容易,并鼓励代码重用。
Python还有一个包含电池的咒语,这意味着对于普通任务,您不需要下载Python语言本身之外的任何其他包。
为了在没有代码过于臃肿的情况下实现这个目标,一组Python模块,a.k.a.标准库,是在您安装Python解释器时安装的。
对于常见的任务,如正则表达式、数学函数和JSON解码,您只需要导入语句,解释器将把这些函数移动到您的程序中。
这个电池包含的咒语是我所认为的Python语言的杀手级功能之一。
最后,Python代码可以从一个相对较小的脚本开始,只包含几行代码,然后发展成为一个完整的生产系统,这对网络工程师来说是非常方便的。
我们很多人都知道,这个网络通常是在没有总体规划的情况下有机增长的。
一种可以随着网络的规模而增长的语言是无价的。
您可能会惊讶地看到,
一种被许多人认为是脚本语言的语言被许多尖端公司(使用Python的组织https://wiki.python.org/moin/OrganizationsUsingPython)使用。
如果你曾经在一个环境中工作过,你必须在不同的供应商平台上切换,比如 Cisco IOS and Juniper Junos,你就知道在试图实现相同的任务时,在语法和使用之间切换是多么痛苦。
由于Python对于小程序和大型程序都足够灵活,因此没有这样戏剧性的上下文切换。
从小到大的Python代码!在本章的其余部分中,我们将对Python语言进行一次高级别的复习。
如果您已经熟悉了基本知识,请随意快速浏览它或跳过本章的其余部分。
有关允许使用和Python 3的更多信息,请参阅https://docs.ansible.com/ansible/2.5/dev_guide/developing_python_3.html。
如前所述,Python是跨平台的。Python程序可以在Windows、Mac和Linux上运行。
实际上,在需要确保跨平台兼容性时,需要特别小心,比如处理Windows文件名中的反斜杠和在不同平台上激活虚拟环境之间的细微差别。
由于这本书是为devop、系统和网络工程师设计的,因此Linux是目标受众的首选平台,特别是在生产过程中。
这本书中的代码将在Linux Ubuntu 18.04 LTS机器上进行测试。
我还将尽我最大的努力确保代码在Windows和macOS平台上运行相同。
如果您对操作系统的细节感兴趣,具体如下:
$ uname -a
Linux network-dev-2 4.18.0-25-generic #26~18.04.1-Ubuntu SMP Thu Jun 27
07:28:31 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
• Extending Python with functions, classes, and packages
❓❓❓ Running a Python programPython程序由一个解释器执行,这意味着代码通过这个解释器输入,然后由底层操作系统执行,并显示结果。
Python开发社区对解释器有几种不同的实现,比如IronPython和Jython。
在这本书中,我们将使用目前使用的最常见的Python解释器CPython。
每当我们在本书中提到Python时,我们都提到的是CPython,除非另有说明。
使用Python的一种方法是利用交互式提示符。
当您想在不编写整个程序的情况下快速测试一段Python代码或概念时,这一点很有用。
交互式模式是Python最有用的特性之一。
在交互式shell中,您可以键入任何有效的语句或语句序列,并立即返回结果。
我通常使用这个来探索我不熟悉的特性或库。交互模式还可以用于更复杂的任务,例如实验数据结构行为,例如,可变和不可变的数据类型。
在Windows上,如果没有返回Python shell提示,您的系统搜索路径中可能没有该程序。
最新的Windows Python安装程序提供了一个将Python添加到系统路径的复选框;确保在安装期间选中。
或者,您可以通过进入环境设置来手动在路径中添加程序。
然而,运行Python程序的更常见方法是保存Python文件并在之后通过解释器运行它。
这将使您不必在相同的语句中反复输入,就像您在交互式shell中必须做的那样。
Python文件只是常规的文本文件,通常保存的扩展名为.py。
在*Nix的世界里,你也可以添加到shebang(#!)在上面指定用于运行文件的解释器。
#字符可用于指定不会由解释器执行的注释。
以下文件helloworld.py具有以下语句:
>>> a = "networking is fun"
>>> b = 'DevOps is fun too'
>>> c = """what about coding?
... super fun!"""
>>>
>>> vendors = ["Cisco", "Arista", "Juniper"]
>>> vendors[0]
'Cisco'
>>> datacenters = ("SJC1", "LAX1", "SFO1")
>>> datacenters[0]
'SJC1'
>>> a
'networking is fun'
>>> a[1]
'e'>>> vendors
['Cisco', 'Arista', 'Juniper']
>>> vendors[1]
'Arista'
>>> datacenters
('SJC1', 'LAX1', 'SFO1')
>>> datacenters[1]
'LAX1'
>>>
>>> a[0:2]
'ne'
>>> vendors[0:2]
['Cisco', 'Arista']
>>> datacenters[0:2]
('SJC1', 'LAX1')
>>> len(a)
17
>>> len(vendors)
3
>>> len(datacenters)
3
>>> b = [1, 2, 3, 4, 5]
>>> min(b)
1
>>> max(b)
5
>>> a
'networking is fun'
>>> a.capitalize()
'Networking is fun'
>>> a.upper()
'NETWORKING IS FUN'
>>> a
'networking is fun'
>>> b = a.upper()
>>> b
'NETWORKING IS FUN'
>>> a.split()
['networking', 'is', 'fun']
>>> a
'networking is fun'
>>> b = a.split()
>>> b
['networking', 'is', 'fun']
>>>>>> routers = ['r1', 'r2', 'r3', 'r4', 'r5']
>>> routers.append('r6')
>>> routers
['r1', 'r2', 'r3', 'r4', 'r5', 'r6']
>>> routers.insert(2, 'r100')
>>> routers
['r1', 'r2', 'r100', 'r3', 'r4', 'r5', 'r6']
>>> routers.pop(1)
'r2'
>>> routers
['r1', 'r100', 'r3', 'r4', 'r5', 'r6']Python列表数据对于存储数据非常好,但是如果我们需要按位置引用数据,那么跟踪数据有时会有点棘手。
接下来我们将看一下Python映射类型。
Python提供了一种映射类型,称为字典。我认为字典是一个穷人的数据库,因为它包含了可以被键索引的对象。
这在其他编程语言中通常被称为关联的数组或哈希表。
如果您在其他语言中使用过任何类似字典的对象,您将知道这是一个功能强大的类型,因为您可以使用人类可读的键来引用该对象。
这个键,而不仅仅是一个项目列表,对那些试图维护和排除代码的穷人来说更有意义。
那个家伙可能是你,在你写代码几个月后,在凌晨2点排除故障。
字典值中的对象也可以是另一种数据类型,例如一个列表。
由于我们对列表使用方括号,对元组使用圆括号,所以我们可以使用花括号来创建字典:
>>> datacenter1 = {'spines': ['r1', 'r2', 'r3', 'r4']}
>>> datacenter1['leafs'] = ['l1', 'l2', 'l3', 'l4']
>>> datacenter1
{'leafs': ['l1', 'l2', 'l3', 'l4'], 'spines': ['r1',
'r2', 'r3', 'r4']}
>>> datacenter1['spines']
['r1', 'r2', 'r3', 'r4']
>>> datacenter1['leafs']
['l1', 'l2', 'l3', 'l4']
Python字典是我最喜欢的网络脚本中使用的数据容器之一。还有其他的数据容器可以派上用场,设置就是其中之一。
集合用于包含无序的无序集合。与列表和元组不同,集合是无序的,不能用数字进行索引。
但是有一个字符使集合非常有用:集合的元素永远不会被复制。
想象您有一个ip列表,您需要放在一个访问列表中。
在这个ip列表中,唯一的问题是它们充满了重复项。
现在,想想您将使用多少行代码来循环浏览ip列表,以整理出唯一的项,一次一个。
但是,内置的集类型允许您只使用一行代码消除重复条目。
老实说,我并没有那么多地使用Python集数据类型,但当我需要它时,我总是非常感谢它的存在。
一旦创建了集合或集合,它们可以使用并集、交集和差异相互比较:
>>> a = "hello"
# Use the built-in function set() to convert the string to a set
>>> set(a)
{'h', 'l', 'o', 'e'}
>>> b = set([1, 1, 2, 2, 3, 3, 4, 4])
>>> b
{1, 2, 3, 4}
>>> b.add(5)
>>> b
{1, 2, 3, 4, 5}
>>> b.update(['a', 'a', 'b', 'b'])
>>> b
{1, 2, 3, 4, 5, 'b', 'a'}
>>> a = set([1, 2, 3, 4, 5])
>>> b = set([4, 5, 6, 7, 8])
>>> a.intersection(b)
{4, 5}
>>> a.union(b)
{1, 2, 3, 4, 5, 6, 7, 8}
>>> 1 *
{1, 2, 3}
>>>现在我们已经研究了不同的数据类型,接下来我们将介绍一下Python操作符。
>>> 1 + 2
3
>>> 2 - 1
1
>>> 1 * 5
5
>>> 5 / 1 #returns float
5.0
>>> 5 // 2 # // floor division
2
>>> 5 % 2 # modular operator
1>>> a = 1
>>> b = 2
>>> a == b
False
>>> a > b
False
>>> a < b
True
>>> a <= b
True
>>> a = 'hello world'
>>> 'h' in a
True
>>> 'z' in a
False
>>> 'h' not in a
False
>>> 'z' not in a
TruePython操作符允许我们有效地执行简单的操作。在下一节中,我们将介绍如何使用控制流来重复这些操作。
if、else和elif语句控制条件代码的执行。
与其他一些编程语言不同,Python使用缩进来构造块。
如人们所料,条件语句的格式如下:
if expression:do something
elif expression:do something if the expression meets
elif expression:do something if the expression meets
...
else:statement下面是一个简单的例子:
>>> a = 10
>>> if a > 1:
... print("a is larger than 1")
... elif a < 1:
... print("a is smaller than 1")
... else:
... print("a is equal to 1")
...
a is larger than 1
>>>
while循环将继续执行,直到条件为False,所以如果您不想继续执行(并崩溃进程),请小心这个循环:
while expression:do something>>> a = 10
>>> b = 1
>>> while b < a:
... print(b)
... b += 1
...
1
2
3
4
5
6
7
8
9
>>>for循环适用于任何支持迭代的对象;这意味着所有的内置序列类型,如列表、元组和字符串,都可以在for循环中使用。
下面的for循环中的字母i是一个迭代变量,所以您通常可以在代码的上下文中选择一些有意义的内容:
for i in sequence:do something
>>> a = [100, 200, 300, 400]
>>> for number in a:
... print(number)
...
100
200
300
400
现在我们已经研究了Python数据类型、操作符和控制流,我们准备将它们分组到称为函数的可重用代码块中。
大多数时候,当您发现自己复制和粘贴一些代码时,您应该将其分解成自包含的函数块。
这种实践允许更好的模块化,更容易维护,并允许代码重用。
Python函数使用带有函数名称的def关键字进行定义,然后是函数参数。
该函数的主体由要执行的Python语句组成。
在函数的末尾,您可以选择向函数调用者返回一个值,或者,默认情况下,如果您不指定一个返回值,它将返回None对象:
def name(parameter1, parameter2):statementsreturn value
我们将在下面的章节中看到更多的函数示例,所以这里是一个快速的示例。
在下面的示例中,我们使用位置参数,所以第一个元素总是被称为函数中的第一个变量。
另一种引用参数的方法是作为具有默认值的关键字,如def减去(a=10,b=5):
>>> def subtract(a, b):
... c = a - b
... return c
...
>>> result = subtract(10, 5)
>>> result
5
>>>
Python函数非常用于将任务分组在一起。
我们可以将不同的函数分组成一个更大的可重用代码片段吗❓
是的,我们可以通过Python类来实现这一点。
Python是一种面向对象的编程(OOP)语言。
Python创建对象的方式是使用类关键字。
Python对象通常是函数(方法)、变量和属性(属性)的集合。
一旦定义了一个类,您就可以创建该类的实例。该类可作为后续实例的蓝图。
OOP的主题超出了本章的范围,所以这里是一个路由器对象定义的简单示例:
>>> class router(object):
... def __init__(self, name, interface_number, vendor):
... self.name = name
... self.interface_number = interface_number
... self.vendor = vendor
...
>>>
一旦定义,您就可以创建任意多的类实例:
>>> r1 = router("SFO1-R1", 64, "Cisco")
>>> r1.name
'SFO1-R1'
>>> r1.interface_number
64
>>> r1.vendor
'Cisco'
>>>
>>> r2 = router("LAX-R2", 32, "Juniper")
>>> r2.name
'LAX-R2'
>>> r2.interface_number
32
>>> r2.vendor
'Juniper'
>>>
当然,关于Python对象和OOP还有很多内容。我们将在未来的章节中看到更多的例子。
任何Python源文件都可以用作模块,事实上,Python文件是一个模块,您在该源文件中定义的任何函数和类都可以被重用。
要加载代码,引用该模块的文件需要使用 import 关键字。当导入文件时会发生三件事:
1、该文件为源文件中定义的对象创建一个新的名称空间
2、调用者执行模块中包含的所有代码
3、该文件在调用者中创建一个引用正在导入的模块的名称。该名称与该模块的名称相匹配
还记得您使用交互式壳层定义的 subtract()函数吗?
为了重用该函数,我们可以将其放入一个名为jomper.py的文件中:
def subtract(a, b):c = a - breturn c
在同一个cotom.py目录下的文件中,您可以启动Python解释器并导入此函数:
>>> import subtract
>>> result = subtract.subtract(10, 5)
>>> result
5
这之所以有效,是因为在默认情况下,Python将首先搜索可用模块的当前目录。
还记得我们之前提到的那个标准库吗?
你猜对了,这些只是被用作模块的Python文件。
❗TIPS:
如果在不同的目录中,可以使用sys的sys.path手动添加搜索路径位置。
软件包允许将一组模块分组在一起。
这进一步组织了Python模块,以获得更多的名称空间保护,以进一步实现可重用性。
包是通过创建一个名称来定义的,然后可以将模块源文件放在该目录下。
为了让Python将其识别为Python包,只需在这个目录中创建一个__init__.py文件。
init.py文件通常可以是一个空文件。
在与减去come.py文件相同的例子中,如果您要创建一个名为math_stuff的目录并创建一个__init__.py文件:
echou@pythonicNeteng:~/Master_Python_Networking/Chapter1$ mkdir math_stuff
echou@pythonicNeteng:~/Master_Python_Networking/Chapter1$ touch math_stuff/__init__.py
echou@pythonicNeteng:~/Master_Python_Networking/Chapter1$ tree
.├── helloworld.py└── math_stuff├── __init__.py└── subtract.py
1 directory, 3 files
您现在引用模块的方式将需要使用点符号包含包名,例如,math_stuff.subtract:
>>> from math_stuff.subtract import subtract
>>> result = subtract(10, 5)
>>> result
5
>>>
正如您所看到的,模块和包是组织大型代码文件和使共享Python代码变得更容易的好方法。
Summary
在本章中,我们介绍了OSI模型,并回顾了网络协议套件,如TCP、UDP和IP。
它们作为处理任意两个主机之间的寻址和通信协商的层一样工作。
这些协议的设计中考虑到了可扩展性,并且在很大程度上与最初的设计没有改变。
考虑到互联网的爆炸性增长,这是一个相当大的成就。我们还快速地查看了Python语言,包括内置的类型、操作符、控制流、函数、类、模块和包。
Python是一种功能强大、易于生产的语言,也易于阅读。
这使得该语言在网络自动化方面成为一个理想的选择。
网络工程师可以利用Python从简单的脚本开始,然后逐步转向其他高级特性。
在 Chapter 2, Low-Level Network Device Interactions,我们将开始研究使用Python以编程方式与网络设备进行交互。


![[python省时间]处理文档,包括批量查找,替换,](https://mutouzuo.oss-cn-hangzhou.aliyuncs.com/my/mudouzuo1.png)