特征重要性评估(Variable importance measure, or Feature importance evaluation,VIM)用来计算样本特征的重要性,定量地描述特征对分类或者回归的贡献程度。随机森林(Random Forest)作为一种强大的机器学习算法,在特征重要性评估方面具有显著优势。特征重要新评估是随机森林的一种自带工具,主要分为两种方法:一种是平均不纯度的减少(mean decrease impurity),常用gini /entropy /information gain测量,现在sklearn中用的就是这种方法;另一种是平均准确率的减少(mean decrease accuracy),常用袋外误差率去衡量。这两种方法的思想都是Leo Breiman提出的,特征重要性评估可以帮助我们理解模型是如何做出预测的,哪些特征对于模型的决策至关重要。
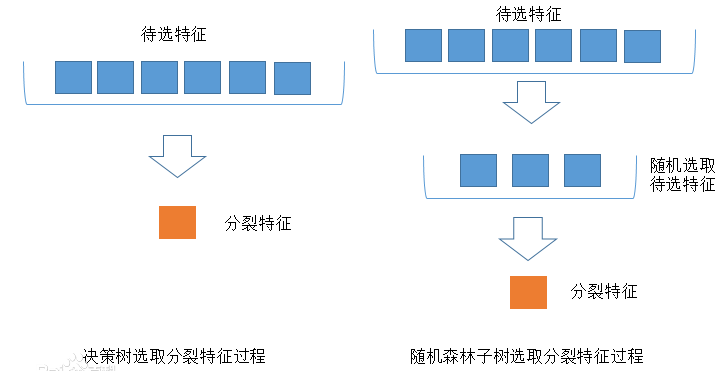
一、特征重要性评估步骤
构建随机森林模型: 首先,需要使用随机森林算法构建一个模型。随机森林由多个决策树组成,每个决策树都是基于对原始数据的不同随机子样本和特征子集的训练而得到的。
评估每个特征的重要性: 随机森林通过对每个特征在树的构建过程中所造成的不纯度减少来评估其重要性。特征重要性可以通过两种方式进行计算:a. Mean Decrease Impurity(MDI): 这种方法通过计算每个特征在每棵决策树中节点划分时的不纯度减少量的平均值来评估特征的重要性。通常情况下,不纯度的衡量指标是基尼不纯度或熵。b. Mean Decrease Accuracy(MDA): 这种方法通过在每个决策树中计算特征对模型准确率的影响来评估特征的重要性。
特征重要性的归一化: 在某些情况下,特征重要性的值需要进行归一化,以便比较不同特征之间的相对重要性。
可视化或排序: 最后,可以将特征重要性的结果可视化,或者按照重要性进行排序,以便更好地理解哪些特征对模型的预测起着关键作用。
二、特征重要性评估的应用
特征重要性评估在各个领域的数据科学和机器学习应用中都有广泛的应用:
金融领域: 在金融领域,特征重要性评估可以帮助银行和金融机构识别最重要的客户特征,用于信用评分、风险管理和欺诈检测等任务。
医疗保健: 在医疗保健领域,特征重要性评估可以用于分析医疗数据,识别对于疾病诊断和预测最为关键的特征,辅助医生进行诊断和治疗决策。
市场营销: 在市场营销领域,特征重要性评估可以帮助企业了解哪些因素对于产品销售和市场推广最为重要,从而优化营销策略和资源分配。
环境科学: 在环境科学领域,特征重要性评估可以用于分析环境数据,识别对于气候变化、环境污染等问题最为关键的特征,为环境保护和可持续发展提供支持。
通过调整随机森林中的参数,如决策树的数量、决策树的最大深度、随机选择特征的数量等,可以进一步优化特征重要性的评估结果。此外,随机森林还可以用于特征选择,通过选择重要性较高的特征来建立更加精确的模型。
三、 随机森林常规的变量重要性评分
在随机森林中,特征的重要性可以通过多种方式进行评估,包括基尼指数(Gini index)和袋外数据(Out-of-Bag,OOB)错误率等。其中,基尼指数是一种衡量特征对分类结果影响的指标,而袋外数据错误率则是通过计算每个特征在随机森林中的每棵树的OOB错误率来评估特征的重要性。现假定有变量 \(( X_1, X_2, \ldots, X_M )\),需要计算出 $ M $ 个变量重要性统计量(VIM),变量 $ X_j$的得分统计量分别用 $ VIM_j^{(Gini)} $ 和 $ VIM_j^{(OOB)} $ 表示。
3.1 Gini指数
统计量 $ VIM_j^{(Gini)}$表示第 \(j\)个变量在随机森林所有树中节点分裂不纯度的平均改变量。Gini指数的计算公式为:
其中,$ K$ 为自助样本集的类别数,$ \hat{p}_{mk} $ 为节点 \(m\)样本属于第\(k\) 类的概率估计值。当样本为二分类数据时(\(K = 2\)),节点\(m\) 的 Gini指数为:
$ \hat{p}_m $ 为样本在节点 $ m $ 属于任意一类的概率估计值。
变量 $ X_j $ 在节点 $ m $ 的重要性,即节点$ m $ 分枝前后 Gini指数变化量为:
其中,$ GI_l $ 和 $ GI_r $ 分别表示由节点$ m $ 分裂的两新节点的 Gini 指数。
如果变量 $X_j $ 在第 $ i $ 棵树中出现 $ M$ 次,则变量 $ X_j$ 在第 $ i $ 棵树的重要性为:
变量 $ X_j $ 在随机森林中的 Gini 重要性定义为:
其中\(n\) 为随机森林中分类树的数量。
3.2 OOB错误率
$VIM_j^{(OOB)} $ 的定义为:在随机森林的每棵树中,使用随机抽取的训练自助样本建树,并计算袋外数据(OOB)的预测错误率,然后随机置换变量$ X_j $ 的观测值后再次建树并计算 OOB 的预测错误率,最后计算两次 OOB 错误率的差值经过标准化处理后在所有树中的平均值即为变量 $ X_j$ 的置换重要性\((VIM_j^{(OOB)})\)。
变量 \(X_j\) 在第 \(i\) 棵树的 $ VIM_j^{(OOB)}$为:
其中,$ n_o^i $ 为第 $ i $ 棵树 OOB 数据的观测例数,$ I(g) $ 为指示函数,即两值相等时取 1,不等时取 0;\(( Y_p \in \{0, 1\} )\) 为第 ( p ) 个观测的真实结果,\(( Y_p^i \in \{0, 1\})\) 为随机置换前第 $ i $ 棵树对 OOB 数据第 \(p\)个观测的预测结果,\(( Y_{p,\pi_j}^i \in \{0, 1\})\)为随机置换后第 $ i $ 棵树对 OOB 数据第 $ p $ 个观测的预测结果。
当变量$ j $ 没有在第 \(i\) 棵树中出现时,$ VIM_{ij}^{(OOB)} = 0$。
变量 $ X_j$ 在随机森林中的置换重要性定义为:
其中\(n\) 为随机森林中分类树的数量。
3.3 分类与回归的MDA方法
MDA方法通过随机交换样本的特征数据,来衡量特征对模型预测准确度的影响。以下是MDA计算的公式,分别对应分类\(MDAc(j)\)和回归\(MDAr(j)\)情形。
- 分类:
- 回归:
其中,\(T\): RF中随机树的数量;\((x_i, y_i)\): 样本,对于分类,\(y_i\)为类别,对于回归为输出(可以是多维);\(X_i^j\): \(X_i\)的第 \(j\) 维(特征)随机交换后的样本;\(D_t\): 随机树\(t\) 的袋外(OOB)样本集,\(D_t^j\): 第\(j\) 维交换后形成的样本集;\(P(X_i)\): 样本 \(X_i\) 的预测结果(类别);\(R(X_i)\):样本 \(X_i\) 的预测输出(回归);\(I(P({X_i})=y_i\) ): 指示函数,如果预测结果与真实类别相同,则返回1,否则返回0;\(y_i^k\): 考虑到多目标回归,表示第\(k\)维输出。
MDA公式反映了对样本第 \(j\) 维特征上的数据进行随机交换后,模型预测(分类)准确度或者(回归)精度下降的程度,使用的是每棵树的袋外数据。如果在随机交换后,准确度下降较多,则认为这个特征比较重要。
上面公式中 \(MDA_c(j)\)、\(MDA_r(j)\) 被称为raw score。对于$MDA_c(j) ,在数值上它反映的是当特征 \(J\) 被随机交换后,袋外样本的平均分类正确率的下降值;对于 \(MDA_r(j)\),在数值上它反映的是当特征 \(j\) 被随机交换后,袋外样本均方误差(MSE)的上升数值。
四、特征重要性的Python代码
4.1 特征比较示例1
一个数据集中往往有成百上千个特征,如何在其中选择比结果影响最大的那几个特征,以此来缩减建立模型时特征数是我们比较关心的问题。这样的方法其实很多,比如主成分分析,lasso等等。用随机森林方法也可以进行特征筛选。随机森林进行特征重要性评估的思想就是看每个特征在随机森林中的每棵树上做了多大的贡献,然后取个平均值,最后比一比特征之间的贡献大小。
# url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data'
# 从这个网址下载数据编辑成数据文件wine.txt,放到工作路径中import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt# 读取数据集
url1 = pd.read_csv(r'wine.txt', header=None)
url1.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash','Alcalinity of ash', 'Magnesium', 'Total phenols','Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins','Color intensity', 'Hue', 'OD280/OD315 of diluted wines', 'Proline']# 将数据集分为特征和标签
x, y = url1.iloc[:, 1:].values, url1.iloc[:, 0].values
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=0)# 构建随机森林模型
forest = RandomForestClassifier(n_estimators=10000, random_state=0, n_jobs=-1)
forest.fit(x_train, y_train)# 获取特征重要性
importances = forest.feature_importances_
feat_labels = url1.columns[1:]
indices = np.argsort(importances)[::-1]# 打印特征重要性
for f in range(x_train.shape[1]):print("%2d) %-*s %f" % (f + 1, 30, feat_labels[indices[f]], importances[indices[f]]))# 设定重要性阈值,筛选变量
threshold = 0.15
x_selected = x_train[:, importances > threshold]# 可视化特征重要性
plt.figure(figsize=(10, 6))
plt.title("红酒数据集中各个特征的重要程度", fontsize=18)
plt.ylabel("Importance level", fontsize=15, rotation=90)
plt.rcParams['font.sans-serif'] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = Falsefor i in range(x_train.shape[1]):plt.bar(i, importances[indices[i]], color='orange', align='center')plt.xticks(np.arange(x_train.shape[1]), feat_labels[indices], rotation=90, fontsize=15)
plt.show()

4.2 特征重要性示例2
使用waveform数据集,训练样本数5000,特征40维,类别数3。RF参数为随机树200棵,分类候选特征数 \(\sqrt{40}\) ,运行5次得到以下特征重要性的柱状图,显示每个特征重要性的平均值及标准差。这个数据是经典的用于特征重要性评估验证的数据集,它的后19维特征是随机噪声,计算结果符合上述情况。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
from sklearn.ensemble import RandomForestClassifier# 加载Waveform数据集
waveform_data = fetch_openml(name='waveform-5000')
X, y = waveform_data.data, waveform_data.target# 训练随机森林模型
clf = RandomForestClassifier(n_estimators=200, max_features='sqrt', random_state=42)
clf.fit(X, y)# 提取特征重要性
feature_importances = clf.feature_importances_# 特征重要性排序
sorted_indices = np.argsort(feature_importances)[::-1]
sorted_features = np.array(waveform_data.feature_names)[sorted_indices]
sorted_importances = feature_importances[sorted_indices]# 绘制前15个特征重要性排序图
plt.figure(figsize=(10, 6))
plt.bar(range(15), sorted_importances[:15], tick_label=sorted_features[:15])
plt.title('Top 15 Feature Importance Ranking')
plt.xlabel('Feature')
plt.ylabel('Importance')
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()

4.3 特征重要性回归示例
使用Tetuan-City-power-consumption数据集来进行试验,原始数据集是通过时间、温度、湿度、风速等6个变量来预测城市3个配电网的能源消耗,即输入6维,输出3维。由于“时间”变量难以使用,所以分解为[minute,hour,day,month,weekday,weekofyear] 6个变量,加上原始的5个气象变量 (temperature, light, sound, CO2 and digital passive infrared (PIR)),形成新的11维输入。随机回归森林的参数为:随机树\(T=200\),分类候选特征数 \(\frac{11}{3}\),节点最小样本数5,最大树深度40,都是默认参数。可以看到hour,month,weekofyear,气温这四个特征(变量)的重要性排名前列,符合常理。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split# 本地数据集路径
file_path = "TetuanCity.csv"# 读取数据
data = pd.read_csv(file_path)# 提取时间特征
data['DateTime'] = pd.to_datetime(data['DateTime'])
data['minute'] = data['DateTime'].dt.minute
data['hour'] = data['DateTime'].dt.hour
data['day'] = data['DateTime'].dt.day
data['month'] = data['DateTime'].dt.month
data['weekday'] = data['DateTime'].dt.weekday
data['weekofyear'] = data['DateTime'].dt.isocalendar().week# 选取特征
features = ['minute', 'hour', 'day', 'month', 'weekday', 'weekofyear','Temperature', 'Humidity', 'Wind Speed', 'general diffuse flows', 'diffuse flows']X = data[features]
y = data[['Zone 1 Power Consumption', 'Zone 2 Power Consumption', 'Zone 3 Power Consumption']]# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练随机回归森林模型
rf = RandomForestRegressor(n_estimators=200, max_features='auto', min_samples_leaf=5, max_depth=40, random_state=42)
rf.fit(X_train, y_train)# 提取特征重要性
feature_importances = rf.feature_importances_# 特征重要性排序
sorted_indices = np.argsort(feature_importances)[::-1]
sorted_features = np.array(features)[sorted_indices]
sorted_importances = feature_importances[sorted_indices]# 绘制特征重要性排序图
plt.figure(figsize=(10, 6))
plt.bar(range(len(features)), sorted_importances, tick_label=sorted_features)
plt.title('Feature Importance Ranking')
plt.xlabel('Feature')
plt.ylabel('Importance')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()

总结
特征重要性评估是在随机森林等机器学习算法中广泛使用的技术。其核心思想是通过量化每个特征对模型预测的贡献度,帮助理解模型的工作原理、进行特征选择和解释模型的决策过程。通过特征重要性评估,可以确定数据集中最具预测性的特征,优化模型的性能,增强模型的解释性和可理解性。评估方法包括基于不纯度减少和准确率下降的计算,可以通过排序和可视化展示特征的重要性。特征重要性评估在金融、医疗、市场营销等领域都有广泛的应用,是数据科学和机器学习中的重要工具之一。特征重要性评估是随机森林算法中的一个重要应用。在随机森林中,特征的重要性可以通过计算每个特征在随机森林中的每棵树上所做的贡献来评估,然后取平均值,最后比较特征之间的贡献大小。这种评估方法有助于在数据集中选择对结果影响最大的特征,从而缩减建立模型时所需的特征数量,随机森林算法在特征重要性评估方面具有很大的优势,能够有效地帮助人们从数据集中选择出对结果影响最大的特征,从而提高模型的精度和性能。
参考资料
- 随机森林特征重要性(Variable importance)评估方法
- 利用随机森林对特征重要性进行评估(公式原理)
- 特征重要度整理 - 随机森林、逻辑回归

![[CISCN 2022 华东北] duck](https://img2023.cnblogs.com/blog/3173791/202405/3173791-20240502231836972-2016892163.png)